👋 欢迎来到我的技术博客!
我是 Cassius0924,目前在字节跳动担任 Golang 开发工程师。
我热衷于开源项目和新技术的探索。
在这里我分享关于编程、技术趋势和开发经验的思考。
如何写好一个 Skill
如何写好一个 Skill?如果只从表面看,Skill 很容易被理解成更长的 Prompt。但实际用下来,Skill 更像是给 Agent 装上的一块可复用能力模块:它告诉模型什么时候应该使用这套方法、具体该怎么执行、执行到什么程度算完成、如何验证自己做对了。 因此,写好一个 Skill 的关键,不是把经验全部塞进 SKILL.md,而是把一类任务中真正会影响结果的知识,组织成 Agent 能稳定调用的工作流。 暂时无法在飞书文档外展示此内容 Skill 是什么?在 Agent Skill 的定义里,一个 Skill 本质上是一个文件夹,里面至少包含一个 SKILL.md 文件。SKILL.md 里会写元信息,比如 name 和 description,也会写具体的执行说明。除此之外,一个 Skill 还可以附带脚本、参考文档、资产文件等资源。 一个典型结构大概是这样: my-skill/ ├── SKILL.md ├── scripts/ ├── references/ └── assets/ 这个结构背后有一个很重要的设计思想:渐进式披露。 Agent 启动时不会把所有 Skill 的完整内容都塞进上下文,而是只读取每个 Skill 的 name 和 description。当用户任务匹配某个 Skill 的描述时,Agent 才会加载完整的 SKILL.md。如果执行过程中还需要更详细的资料,再按需读取 references/、assets/ 或执行 scripts/ 里的内容。 所以,Skill 的第一个门槛不是“内容写得多不多”,而是:它能不能在正确的时机被触发。 description 是触发器,不是简介Skill 写得再好,触发不了等于零。Agent 只在启动时加载每个 Skill 的 name 和 description,靠这两行决定"要不要把这个 Skill 拉进来"。描述写不好,Skill 永远不会被调用。 很多人会把 description 写成 Skill 简介: ...
烧录树莓派系统镜像指南
我把尘封已久的 树莓派4B 拿出来,准备重新使用它,结果发现我进不去系统了 😇。。。 因为忘记了 Hostname 和 Password,手上没有 TTL 转串口线,也没有 micro HDMI 转 HDMI 线,无法通过串口或者显示器进行恢复。 不过正好有一个 micro SD 卡读卡器,可以通过重新烧录系统镜像的方式来恢复树莓派的使用。 准备工作 一台 macOS/Linux/Windows 电脑,我这里以 macOS 为例 一个 micro SD 卡读卡器 如果你是 MacBook,你多半没有 USB-A 接口,需要一个 USB-A(母)转 USB-C(公)的转接头。 步骤下载树莓派官方烧录工具前往树莓派官网下载官方烧录工具 Raspberry Pi Imager,根据你的操作系统选择对应的版本进行下载和安装。这里不赘述。 将 SD 卡插入读卡器并连接电脑这很简单吧,怎么插就不展示了。 烧录配置打开安装好的 Raspberry Pi Imager。 选择设备型号 选择你的树莓派的型号,我是树莓派 4B,我这里选择 Raspberry Pi 4。 不知道树莓派型号的话,看看你的板子,找找板上的小字,一般会有型号标识。 选择操作系统 选择你想要烧录的操作系统,一般都选择 Raspberry Pi OS (64-bit)。 选择存储设备 选择你插入的 SD 卡读卡器对应的存储设备。如果你的电脑只插了 配置 Hostname ...
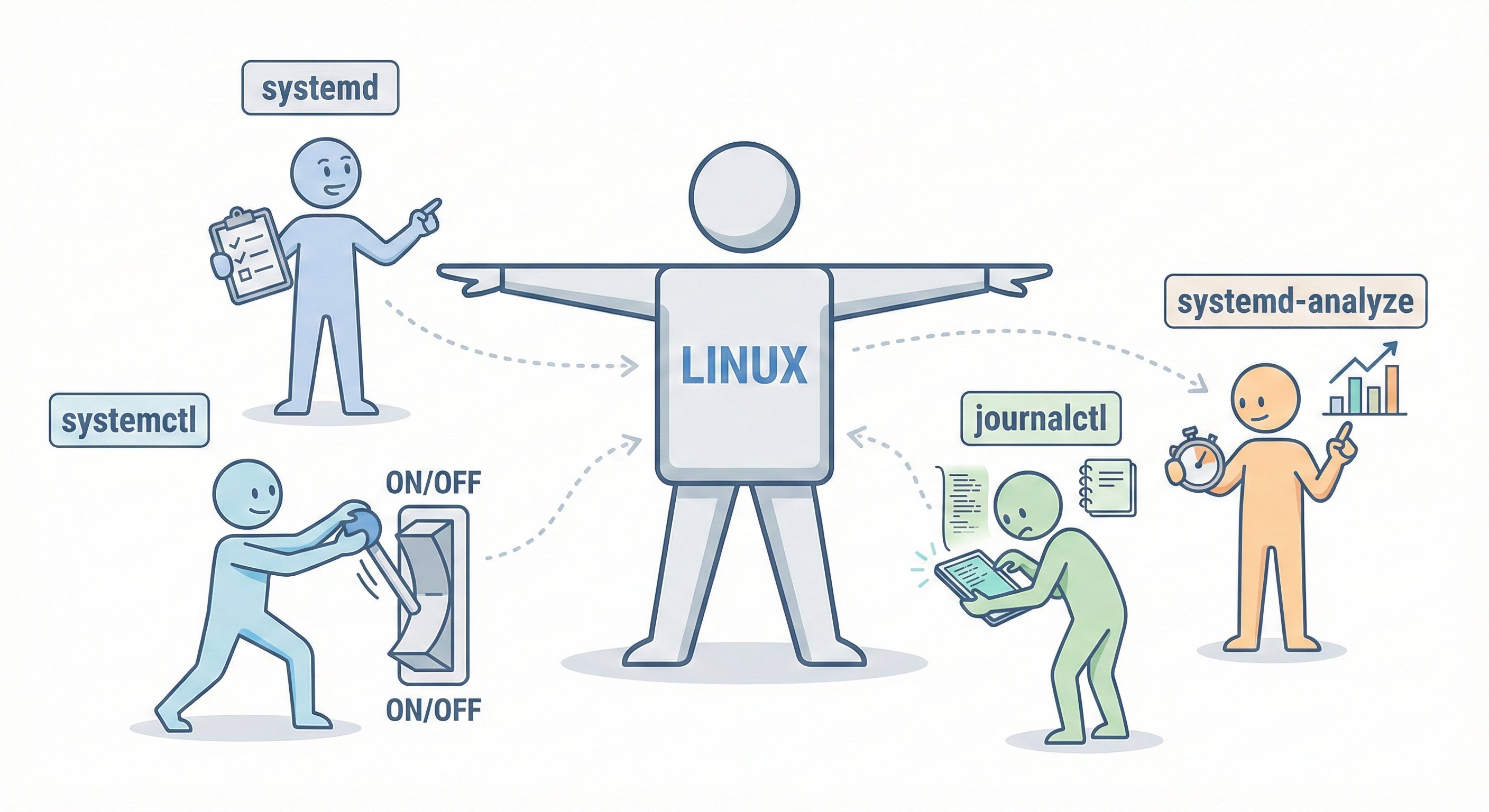
使用 systemd 优雅的管理自启动服务
systemd 是现代 Linux 发行版中广泛使用的初始化系统和服务管理器。它不仅提供了强大的功能来管理系统服务,还允许用户轻松地配置和管理自启动服务。 systemd 中的字母 d 表示 (daemon)守护进程,相信学过操作系统的同学都知道守护进程是指在后台运行的进程。 systemd 作为守护进程管理器,负责启动、停止和管理系统中的各种服务。 systemd 操作命令systemctlsystemctl(system control)是 systemd 的主要命令行工具。它用于检查和控制 systemd 系统和服务管理器的状态。 刷新配置文件 sudo systemctl daemon-reload 但你修改了服务的配置文件后,需要运行这个命令来让 systemd 重新加载配置文件。否则 systemd 不会识别你的更改。 启动服务 sudo systemctl start <service_name> 这个命令用于启动指定的服务,当系统重启后,服务不会自动启动。 停止服务 sudo systemctl stop <service_name> 这个命令用于停止指定的服务。 重启服务 sudo systemctl restart <service_name> 这个命令用于重启指定的服务。 重新加载服务配置 sudo systemctl reload <service_name> 这个命令用于重新加载指定服务的配置,而不停止服务。它与 restart 的区别在于,reload 不会中断服务的运行,适用于支持热加载配置的服务。 查看服务状态 sudo systemctl status <service_name> 这个命令用于查看指定服务的当前状态。 启用服务自启动 sudo systemctl enable <service_name> 这个命令用于使指定的服务在系统启动时自动启动。但是不会立即启动服务,如果想立即启动服务,可以加上 --now 选项: sudo systemctl enable --now <service_name> ...
使用 Certbot 申请泛域名 SSL 证书指南
使用 Certbot 申请泛域名证书并不复杂,几个月前搞过,但是又忘了,今天重新搞了一遍,记录一下步骤。 前提条件 你需要有一个域名,并且可以管理该域名的 DNS 记录。 一般我们都是在 阿里云 或 火山引擎 等云服务商购买的域名,这里以阿里云为例。 申请泛域名证书安装 Certbot先用 certbot --version 检查是否已经安装 Certbot,如果没有安装,下面一句话安装一下: sudo apt install certbot -y 申请证书泛域名证书需要通过 DNS-01 验证域名所有权,使用以下命令申请,注意将 *.cassdev.com 和 cassdev.com 替换为你的域名,example@google.com 替换为你的邮箱。 笔记 什么是 DNS-01 验证? ...
LLM 参数之 Temperature 和 Top-p
大家在使用 LLM 生成内容时,不知道有没有注意到 LLM 的一些可配置参数,比如 Temperature 和 Top-p,是否关注过这些参数的作用? 无论是在 OpenAI 的 API 文档、Google 的 AI Studio、以及各种的 AI 平台,你都能看到它的身影。 什么是 Temperature 和 Top-p?在与 LLM 聊天时,大家可能已经注意到,有的 Agent 十分有创造力,有的 Agent 又十分严谨。这其中除了 Prompt 的影响外,还有一个重要的因素就是 LLM 的采样参数,包括 Temperature 和 Top-p。 提示 TL;DR ...

LLM 参数之 Response Format
如果想让 LLM 输出 JSON 格式的内容,大家第一反应会是什么?可能大多数人和我一样,直接在提示词中写上"请输出 JSON 格式的内容,格式为 { “key”: “value” }"。但其实,这种方式并不是最优的。 从之前我们也了解到了,LLM 的输出是一个概率性的文本补全器。单纯依靠提示词工程来控制 LLM 的输出格式并不可靠。用自然语言去描述一个复杂的 JSON 结构本就不易,再加上当提示词很长时,LLM 的注意力可能会分散,这些因素都容易导致它输出不符合预期的格式,甚至根本不输出 JSON。 具体来说,这种方式可能会遇到以下三个主要问题: 混入无关文本:模型可能在 JSON 对象前后添加对话式的"口水话",如"好的,这是您要的 JSON:…",这给后续的程序化解析带来了困难。 结构性错误:生成的 JSON 可能存在语法错误,例如缺少逗号、括号不匹配或引号使用不当,导致解析失败。 内容幻觉:模型可能"幻觉"出指令中未要求的字段,或遗漏必要的字段,破坏了数据模式的一致性。 让 LLM 生成符合预期的 JSON 格式内容的最佳实践是使用 response_format 参数,在程序算法的层面上去干预 LLM 的输出格式。这个参数允许我们让 LLM 进行结构化内容输出,确保 LLM 生成的内容符合预期的结构和语法。 Response Format 参数response_format 参数在绝大多数现代 LLM API 中都可用,允许开发者指定模型输出的格式。 DeepSeek API Response Format OpenAI API Response Format DouBao API Response Format 通过这个参数,我们可以明确要求 LLM 生成特定格式的内容,如 JSON 对象、纯文本或符合 JSON Schema 的数据结构。 response_format 参数支持以下三个模式: ...
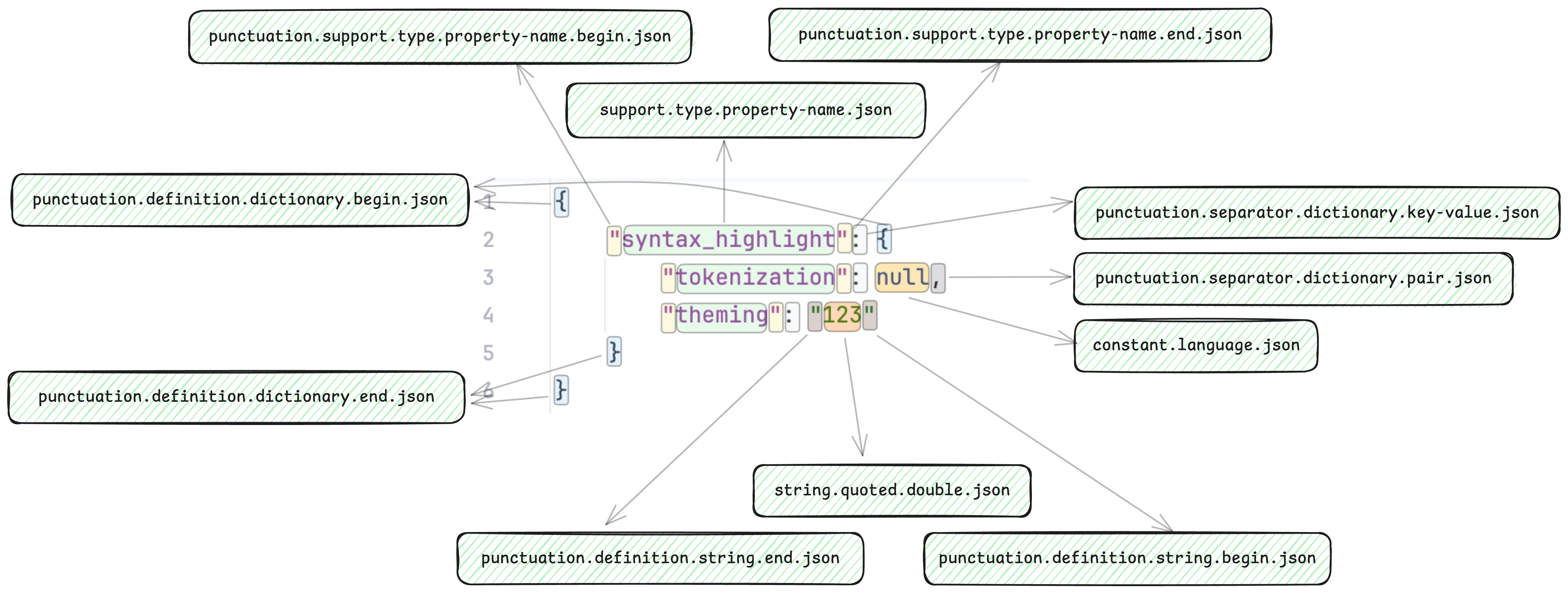
浅析 Textmate 语法高亮规则运行机制
1. 语法高亮简介语法高亮是指在IDE或编辑器中,对文本进行分词,即将文本拆解为 Token(标记),每个 Token 都有对应的名称(作用域)进行标记。再配合主题样式规则,对不同名称的 Token 的进行主题化,以提高代码的可读性。 程序员离不开语法高亮,就像作家离不开标点符号一样。(你可以代入一下使用 txt 文本编辑器写代码的场景) 语法高亮由两个部分组成: 分词(Tokenization):将文本拆解为一系列 Token。 主题化(Theming):对 Token 进行样式渲染,如字体颜色、背景色、加粗等。 我们以 JSON 的语法为例,简单介绍一下语法高亮的过程。 首先分词引擎会对 JSON 文本进行分词,下图是将 JSON 文本进行分词后的结果,其中每个矩形所包括的文本都是一个 Token,每个 Token 都有一个作用域名称,例如 null 对应的是 constant.language.json 作用域。 然后主题化引擎会根据 Token 的作用域名称,对 Token 进行样式渲染,例如将 constant.language.json 作用域映射为蓝色不加粗字体。那么 null 就会被渲染为蓝色不加粗字体。 2. 分词的实现方式目前主流的分词实现方式大致有有以下三种: 基于正则表达式的分词:Textmate 基于词法分析的分词:Highlight.js 基于语法树的分词:Tree-sitter (如果有其他,欢迎补充) 本文只讨论 Textmate 的语法高亮规则编写。 Textmate 原是 MacOS 下的一款文本编辑器,其语法高亮规则是基于正则表达式的,但由于其规则简单易懂,且支持多种语言,因此被广泛应用于各种编辑器和IDE中,如 VSCode、Sublime Text 等。JetBrains 的 IDE 也集成了 Textmate Bundle 插件,可以直接导入 Textmate 的语法高亮规则。 ...
Vim 技能补全计划
适合已经熟悉 Vim 基础操作,希望提高编辑技能的开发者的实用技巧集合
Socket 编程之 epoll 源码分析学习笔记
本文基于 Linux 6.9 内核源码进行分析。 几个数据结构 eventpoll这是 epoll 的主要数据结构,它用于存储 epoll 的相关信息,包括等待队列、就绪队列、红黑树等。 struct eventpoll { wait_queue_head_t wq; // epoll 的等待队列:用于存储等待的进程/线程,指向等待队列头 wait_queue_head_t poll_wait;// 这个 poll_wait 等待队列只有在 epoll 嵌套的情况下才会用到 struct list_head rdllist; // 就绪队列:用于存储就绪的 fd,指向就绪队列头 struct rb_root_cached rbr; // 红黑树:用于存储所有的 fd,指向红黑树根节点 struct wakeup_source *ws; // 一个唤醒源,用于唤醒进程 }; epitemepitem 的作用是将 fd、就绪队列、红黑树节点等信息封装在一起。 struct epitem { union { struct rb_node rbn; // 红黑树节点,用于存储 fd,指向红黑树节点 struct rcu_head rcu; // 用于释放 epitem }; struct list_head rdllink; // 就绪队列节点,用于存储就绪的 fd,指向就绪队列节点 struct eventpoll *ep; // 指向 eventpoll struct epoll_filefd ffd; // epoll 文件描述符 struct wakeup_source *ws; // 一个唤醒源,用于唤醒进程 struct epoll_event event; // 监听的事件 }; ep_pqueue给 poll 队列封装的结构体,用于存储 poll_table 和 epitem。 ...
C++ 内存模型学习笔记
C++ 内存模型从上(高地址)到下(低地址)可以分为以下几个部分: 栈区:由编译器自动分配释放,存放函数的参数值、局部变量的值等。 堆区:由程序员分配释放,若程序员不释放,程序结束时可能由操作系统回收。 全局/静态区:分为 .data 段(全局初始化区)和 .bss 段(全局未初始化区),.data 段存放 已初始化 了的全局变量和静态变量,.bss 段存放 未初始化 的变量。 常量区:就是 .rodata 段,存放常量。 代码区:存放函数体的代码。