如果想让 LLM 输出 JSON 格式的内容,大家第一反应会是什么?可能大多数人和我一样,直接在提示词中写上"请输出 JSON 格式的内容,格式为 { “key”: “value” }"。但其实,这种方式并不是最优的。
从之前我们也了解到了,LLM 的输出是一个概率性的文本补全器。单纯依靠提示词工程来控制 LLM 的输出格式并不可靠。用自然语言去描述一个复杂的 JSON 结构本就不易,再加上当提示词很长时,LLM 的注意力可能会分散,这些因素都容易导致它输出不符合预期的格式,甚至根本不输出 JSON。
具体来说,这种方式可能会遇到以下三个主要问题:
混入无关文本:模型可能在 JSON 对象前后添加对话式的"口水话",如"好的,这是您要的 JSON:…",这给后续的程序化解析带来了困难。
结构性错误:生成的 JSON 可能存在语法错误,例如缺少逗号、括号不匹配或引号使用不当,导致解析失败。
内容幻觉:模型可能"幻觉"出指令中未要求的字段,或遗漏必要的字段,破坏了数据模式的一致性。
让 LLM 生成符合预期的 JSON 格式内容的最佳实践是使用 response_format 参数,在程序算法的层面上去干预 LLM 的输出格式。这个参数允许我们让 LLM 进行结构化内容输出,确保 LLM 生成的内容符合预期的结构和语法。
Response Format 参数
response_format 参数在绝大多数现代 LLM API 中都可用,允许开发者指定模型输出的格式。
通过这个参数,我们可以明确要求 LLM 生成特定格式的内容,如 JSON 对象、纯文本或符合 JSON Schema 的数据结构。
response_format 参数支持以下三个模式:
| 模式 | 描述 | 备注 |
|---|---|---|
text | 生成纯文本内容。适用于需要自然语言回复的场景。 | 默认模式,不会对输出格式进行约束。 |
json_object | 生成 JSON 对象。适用于需要结构化数据的场景。 | 早期的 JSON 模式,只能保证输出为 JSON 格式,但不能 JSON 结构符合预期 |
json_schema | 生成符合指定 JSON Schema 的 JSON 对象。适用于需要严格数据格式的场景。 | 结构化输出模式,这是官方推荐的模式,可以确保输出的 JSON 符合预定义的结构和类型约束。 |
使用
json_schema模式时,需编写符合 JSON Schema 规范的模式定义,点击即刻学习 JSON Schema :)
json_object 和 json_schema 的差别,前者会能够保证输出为 JSON 格式,但具体字段和类型需要通过 Prompt 来引导。后者则可以通过 JSON Schema 来定义输出 JSON 的结构和类型,Prompt 只需要关注任务本身,而不需要关心格式。
工作原理
我们都知道,Transformer 是大多数现代 LLM 的基础架构。但 response_format 参数并不作用于 Transformer 模型的内部,而是在其生成流程中加入了一个约束步骤。这个约束步骤发生在 Transformer 的 Linear 层之后、Softmax 层之前。
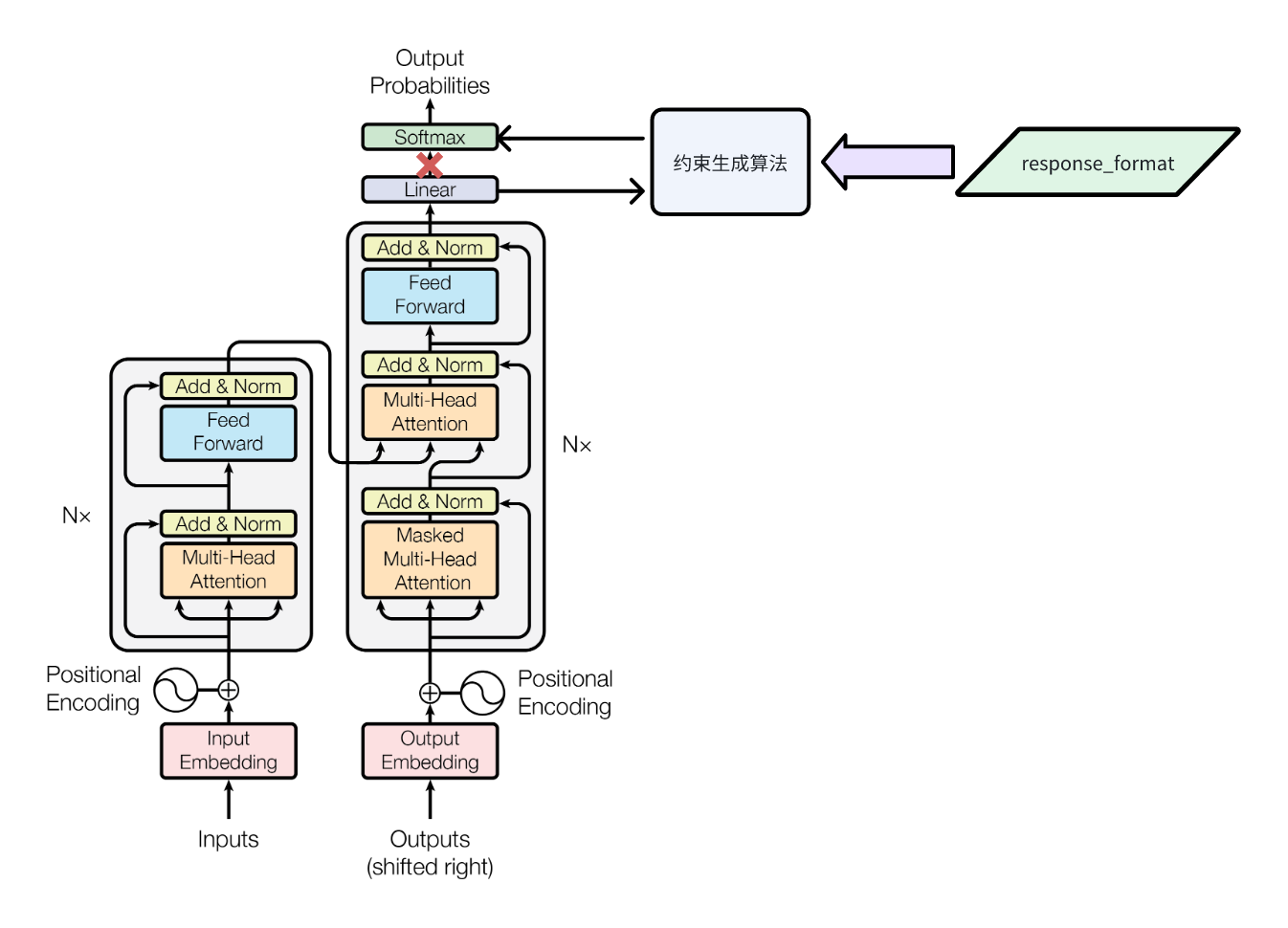
下面是 Transformer 生成每个词(token)的过程:
Linear 层 → Logits 原始分数 → Softmax 层 → 概率 -> token 采样 -> 输出
在 Transformer 生成每个词(token)的过程中,LLM 首先通过 Linear 层计算出每个可能词的原始分数(logits),然后通过 Softmax 层将这些分数转换为概率分布。接下来,LLM 会根据这个概率分布进行随机采样。
如果使用了 response_format 参数,LLM 会对 Logits 原始分数进行一轮处理,这个过程交给了 LogitsProcessor 来完成。加上 LogitsProcessor 后,Transformer 的生成流程变为:
Linear 层 → Logits 原始分数 → Logits 处理器 -> 处理后的 Logits 分数 → Softmax 层 → 概率 -> token 采样 -> 输出
在约束生成算法的实现上,主要使用两种类型的语法:
- 正则表达式(Regular Expression):用于定义输出内容必须遵循的字符模式。通过正则表达式,我们可以精确描述诸如 JSON 对象结构等复杂格式要求。
- BNF(Backus-Naur Form):这是一种标准的上下文无关文法表示法,广泛应用于编程语言语法的精确定义,能够描述更复杂的层次化结构。
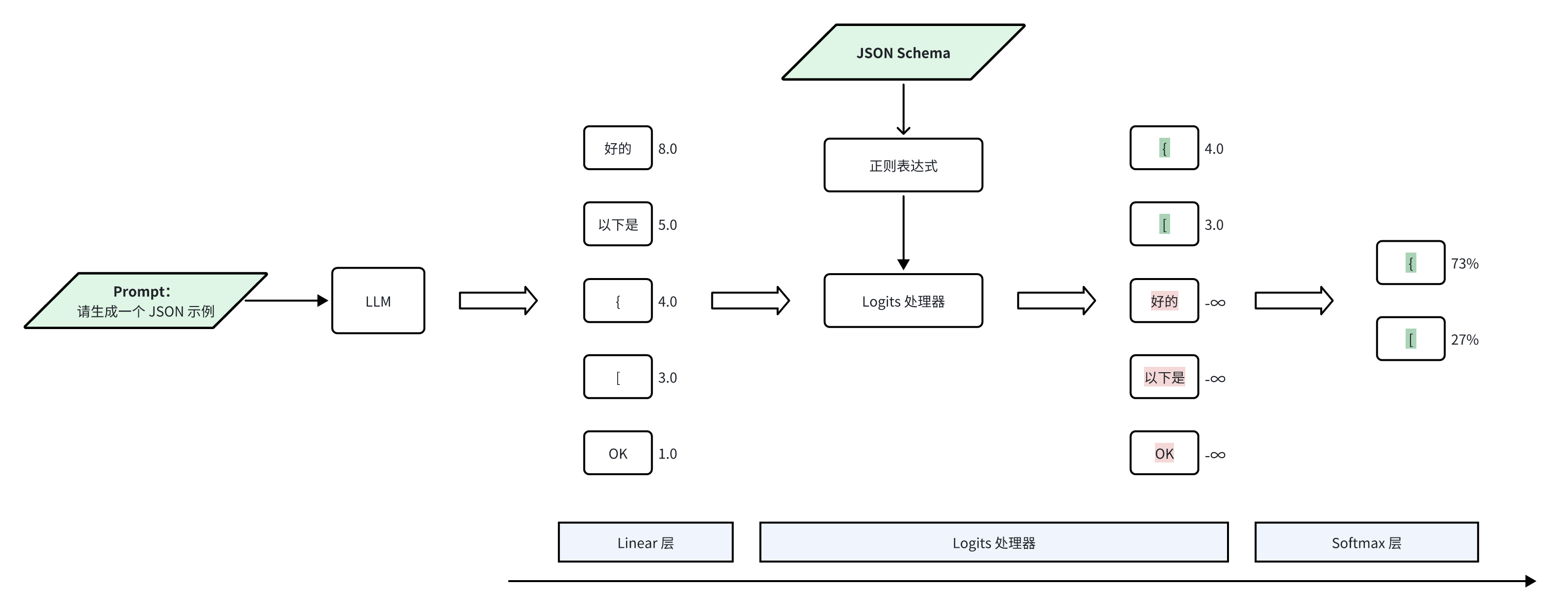
这里用大家更熟悉的正则表达式来举例说明,在应用了 response_format 参数后,LLM 输出 token 的过程如下:
- Logits 计算:Transformer 的 Linear 层为词汇表中的每个候选 token 计算出原始分数(logits)。
- 约束过滤:LogitsProcessor 根据预定义的正则表达式对这些分数进行筛选,将候选 token 分为两类:符合格式要求的"合法 token"和不符合要求的"非法 token"。
- 分数调整:LogitsProcessor 保持合法 token 的原始分数不变,但将所有非法 token 的分数设置为负无穷(-∞)。
- 概率归一化:Softmax 层处理调整后的分数。由于非法 token 的分数为 -∞,经过指数函数和归一化后,它们的概率会趋近于 0。
- token 采样:采样器根据最终的概率分布选择输出,此时只有合法 token 具有非零概率,从而确保输出符合预期格式。
下图展示了使用 Response Format 参数后,LLM 生成 token 的流程:
更多关于 Response Format 参数的细节,可以参考 OpenAI 的官方文档 OpenAI API Structured Outputs。
使用示例
在不使用 response_format 参数的情况下,我们可能会使用如下的 Prompt 去引导 LLM 生成符合特定格式的内容:
# 角色
你是一位专业的数学题解答者,擅长解答各种数学问题,并能提供详细的解题步骤。
## 任务
请解答以下数学题,并将答案以 JSON 格式返回,格式如下:
{
"answer": "答案",
"steps": [
{
"explanation": "该步骤的解释说明,描述该步骤的计算过程和逻辑",
"output": "该步骤的计算方程式,只允许包含数字、运算符、等号和括号,不允许包含其他字符",
"operation": "该步骤的数学运算类型,枚举值为 add, sub, mul, div, pow"
}
]
}
## 例子
### Prompt
"请解答以下数学题:10-(1^2 + 34) = ?"
### 你的回答
{
"answer": "-25",
"steps": [
{
"explanation": "计算 1 的平方",
"output": "1^2",
"operation": "pow"
},
{
"explanation": "计算 1^2 + 34",
"output": "(1^2 + 34)",
"operation": "add"
}
]
}
## 限制
1. 输出内容必须严格遵循 JSON 格式,不能包含任何多余的文本。
2. 生成的 JSON 对象必须包含 `answer` 和 `steps` 两个字段。
3. `steps` 字段必须是一个数组,包含解题的每个步骤。
4. 每个步骤必须包含 `explanation`、`output` 和 `operation` 三个字段。
5. `operation` 字段的值必须是 "add"、"sub"、"mul"、"div" 或 "pow" 中的一个。
6. `output` 字段的值只能包含数字、运算符、等号和括号,不允许包含其他字符。
在上下文较短时,上述提示词能够有效引导模型生成符合预期的 JSON 内容,足以应对聊天应用中的日常问答场景(比如作为 Chat 应用中的一个角色)。
但在开发者视角上,在实际应用场景中,调用 API 时需要遵循最佳实践,使用 response_format 参数来确保 LLM 输出符合预定义的 JSON 结构。
下面以 Go 语言为例,展示如何使用 OpenAI API 的 response_format 参数来生成符合 JSON Schema 的响应格式。
package main
import (
"context"
"encoding/json"
"fmt"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
const jsonSchema = `
{
"type": "object",
"properties": {
"steps": {
"type": "array",
"items": {
"type": "object",
"properties": {
"explanation": {
"type": "string",
"description": "该步骤的解释说明,描述该步骤的计算过程和逻辑"
},
"output": {
"type": "string",
"description": "该步骤的计算方程式,只允许包含数字、运算符、等号和括号,不允许包含其他字符"
},
"operation": {
"type": "string",
"description": "该步骤的数学运算类型",
"enum": ["add", "sub", "mul", "div", "pow"]
}
},
"required": [ "explanation", "result", "hard_level" ],
"additionalProperties": false
}
},
"answer": {
"type": "string"
}
},
"required": [ "steps", "answer" ],
"additionalProperties": false
}
`
func main() {
var jsonSchemaMap map[string]any
if err := json.Unmarshal([]byte(jsonSchema), &jsonSchemaMap); err != nil {
fmt.Println("Error parsing JSON schema:", err)
return
}
client := openai.NewClient(
option.WithAPIKey("<YOUR-API-KEY>"),
)
prompt := "请解答以下数学题:10-(2^2 + 34) = ?"
jsonSchema := openai.ResponseFormatJSONSchemaJSONSchemaParam{
Name: "answer_response",
Description: openai.String("解答数学题的响应格式"),
Schema: jsonSchemaMap,
Strict: openai.Bool(true),
}
ctx := context.Background()
response, err := client.Chat.Completions.New(ctx, openai.ChatCompletionNewParams{
Model: "gpt-4o-mini",
Messages: []openai.ChatCompletionMessageParamUnion{
openai.SystemMessage(prompt),
},
ResponseFormat: openai.ChatCompletionNewParamsResponseFormatUnion{
OfJSONSchema: &openai.ResponseFormatJSONSchemaParam{
JSONSchema: jsonSchema,
},
},
})
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(response.Choices[0].Message.Content)
}
可以看到我们的 Prompt 长度被大大缩短了,能够把 Prompt 聚焦在任务本身,而不是格式上。
这里使用的是手写 JSON Schema 的方式来约束输出格式。对于 Python 语言,可以直接使用 pydantic 库来定义数据结构,能够自动生成 JSON Schema,具体参考 Structured Outputs。对于 Go 语言,可以使用 invopop/jsonschema 库来生成 JSON Schema。
快速生成 JSON Schema
笔者在摸索的过程中发现了 OpenAI 官方文档里有一个功能可以利用 GPT 快速生成 JSON Schema。只需要丢给 GPT 一个 JSON 示例,它就能自动生成对应的 JSON Schema。我们可以利用这个功能快速生成符合预期的 JSON Schema 初稿,然后在这基础上进行修改和完善。
进入 OpenAI 官方文档的 Structured Outputs 页面,点击 “Generate” 按钮,然后粘贴上 JSON 示例,过一会就会在下面生成对应的 JSON Schema。