大家在使用 LLM 生成内容时,不知道有没有注意到 LLM 的一些可配置参数,比如 Temperature 和 Top-p,是否关注过这些参数的作用?
无论是在 OpenAI 的 API 文档、Google 的 AI Studio、以及各种的 AI 平台,你都能看到它的身影。
什么是 Temperature 和 Top-p?
在与 LLM 聊天时,大家可能已经注意到,有的 Agent 十分有创造力,有的 Agent 又十分严谨。这其中除了 Prompt 的影响外,还有一个重要的因素就是 LLM 的采样参数,包括 Temperature 和 Top-p。
TL;DR
二者都是用于控制 LLM 生成内容随机性的参数。它们就像旋钮,通过调节它们来决定 LLM 输出的“保守”程度或“冒险”程度。
temperature通过调整 token 生成的概率分布来控制输出的随机性top_p通过限制 LLM 考虑的 token 范围来控制输出的随机性
一个简单的例子
为了更好地理解 temperature 和 top_p 如何影响概率,让我们想象一个场景:
假设 LLM 正在生成一句话:“我想吃___。”,下面是 LLM 待选的 token 列表:
- 水果 (60%)
- 零食 (20%)
- 饺子 (10%)
- …
- 大蒜 (0.01%)
- 螺丝 (0.001%)
- 汽油 (0.0001%)
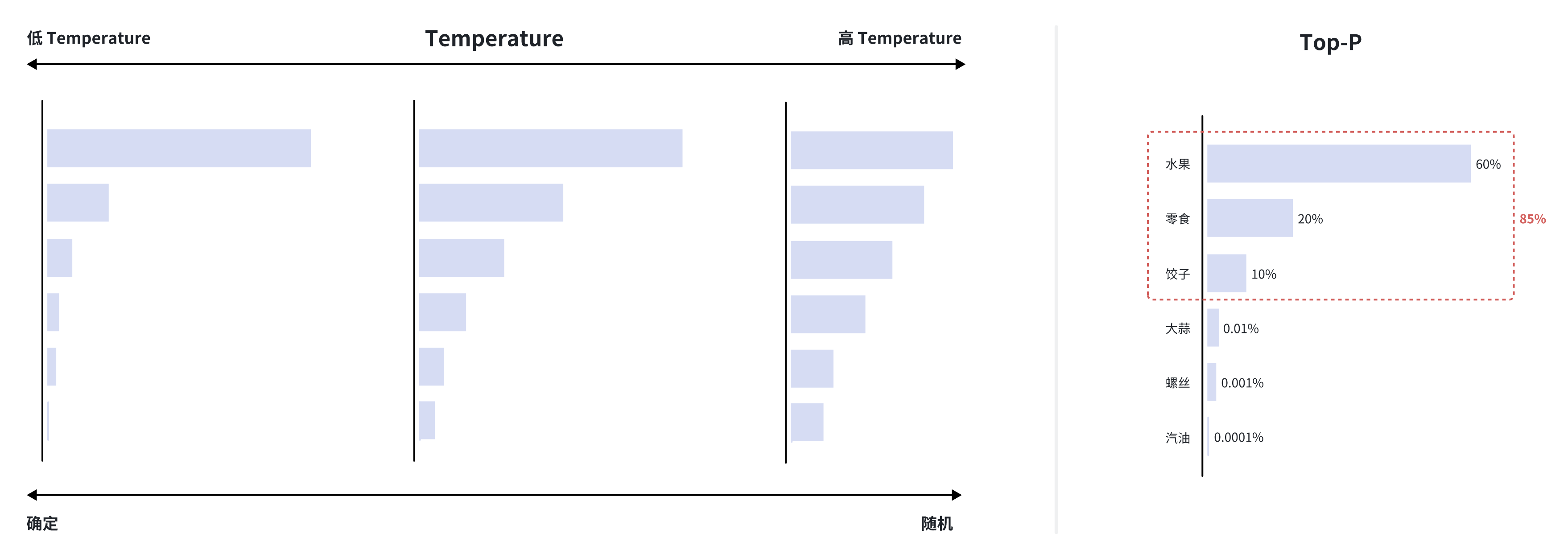
Temperature: 在默认情况下(
temperature=1),LLM 很可能会选择“水果”或“零食”。但如果我们提高temperature -> 1.7,那些低概率的选项,如“大蒜”或“螺丝”,被选中的可能性就会增加,从而让句子变得出人意料。反之,如果我们降低temperature -> 0.2,LLM 几乎只会选择“水果”,输出会更为确定。Top-p: 默认
top_p=1时,LLM 会考虑所有 token 的概率分布,也就是说 LLM 存在选择“汽油”或“螺丝”的可能性。但如果我们设置top_p=0.85,LLM 只会考虑累计概率达到 85% 的最小 token 集合,也就是“水果”+“零食”+“饺子”=90% >= 85%,这样 LLM 就只会在这三个选项中进行选择,输出更加符合常理。
Transformer 的 Linear 层和 Softmax 层
在介绍
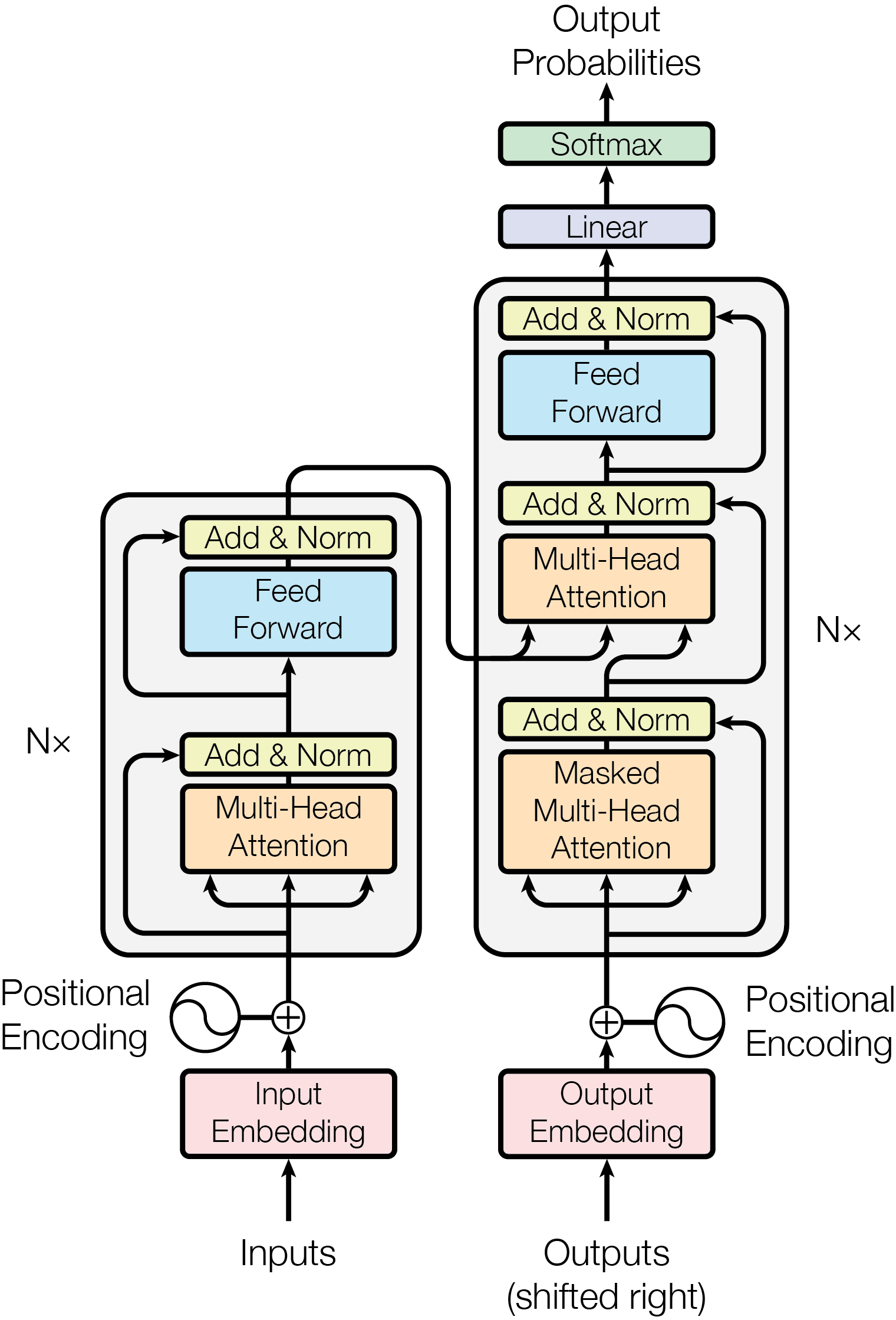
temperature和top_p的工作原理前,我们需要简单了解一下 Transformer 模型(大多数现代 LLM 的基础架构)的内部机制。
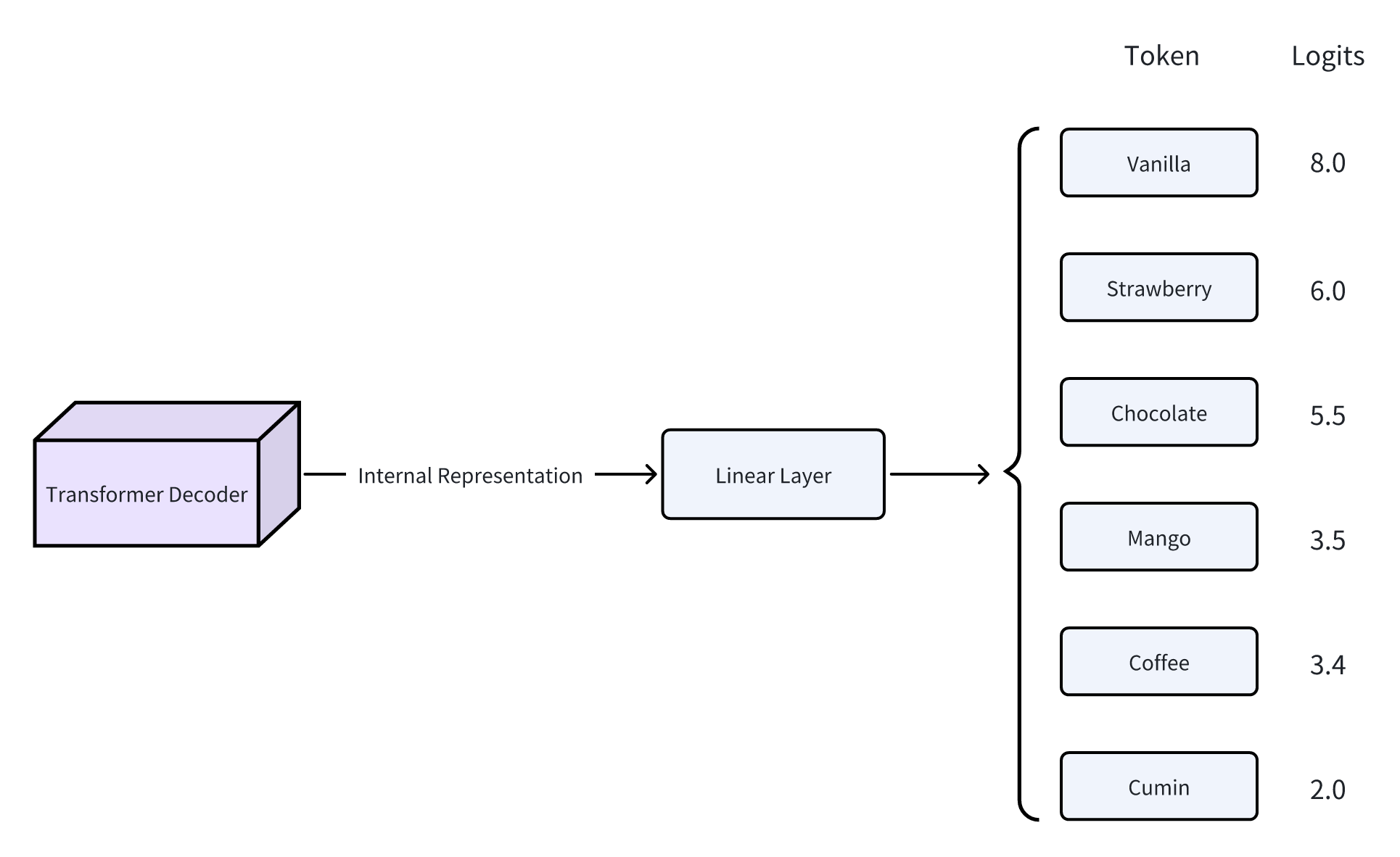
想必大家都见过这张 Transformer 的架构图,它自 LLM 的开山鼻祖论文 Attention Is All You Need。可以看到在架构图的输出端最后接了一个 Linear 层和 Softmax 层,这就是模型生成每个词的概率分布的地方。
Linear 层
解码器的输出会经过 Linear 层,由 Linear 层将 LLM 的内部表示翻译每个 token 的原始分数,称为 Logits。每个 logit 值代表了 LLM 对于相应 token 是句子中下一个正确 token 的置信度(该词作为下一个词的“合理性”)。该层有效地将模型内部的、抽象的语义表征“翻译”为在整个 token 词汇表上的具体预测。
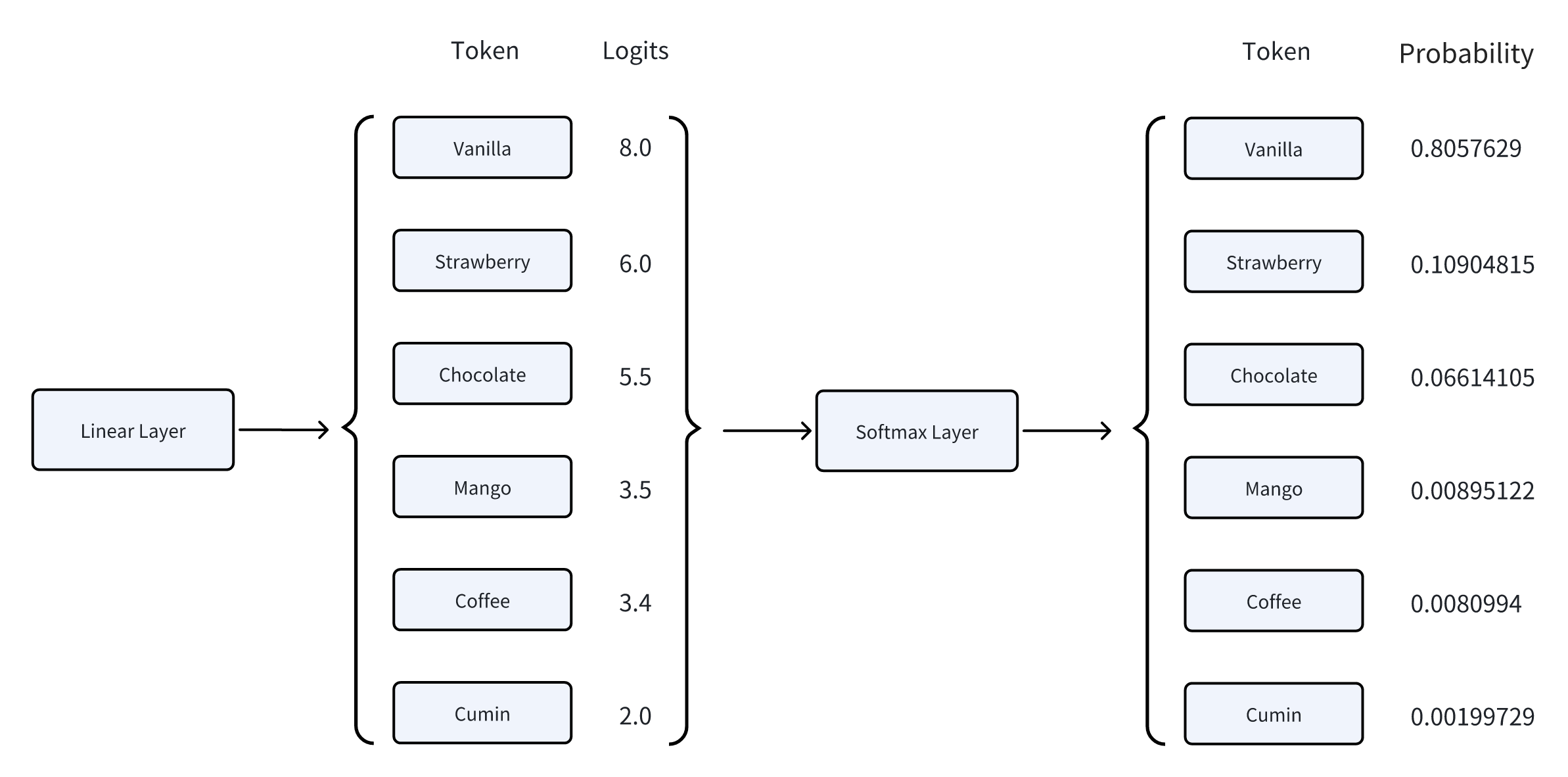
Softmax 层
Softmax 主要是将 Linear 层输出的 logits 转换为一个概率分布。这一转换过程分为两个步骤:
- 指数化:对每个 logit 应用指数函数,得到一个非负值。
- 归一化:将所有指数化后的值进行归一化处理,使得它们的总和为 1,从而形成一个概率分布。
Softmax 的具体数学模型如下:
$$ P(token_i) = softmax(logit_i) = \frac{e^{logit_i}}{\sum_{j} e^{logit_j}} $$
其中:
- $P(token_i)$ 是第 $i$ 个词的最终概率。
- $logit_i$ 是第 $i$ 个词的原始分数。
插曲:Softmax 为什么叫 Softmax?
除了 Softmax 函数,还有一种叫 Hardmax 的函数。
- Hardmax(严格 argmax):会将最大元素对应位置输出 1,其它位置输出 0;
- Softmax(平滑 argmax):最大元素会获得更高但不绝对的概率,其它元素也会有一定概率。
所以 Softmax 的意思是“平滑的最大化参数”,它允许模型在生成时考虑多个可能的选项,而不是仅仅选择一个最可能的选项。
只有使用 Softmax 函数,才能将原始分数转换为概率分布。而 Hardmax 函数则会将最大分数对应的词的概率设为 1,其它词的概率设为 0,这样就没有随机性了。
Temperature 和 Top-p 的工作原理
Temperature 的工作原理
现在我们了解了 Logits 是什么,以及 Softmax 函数的作用。那么就可以来看看 temperature 是起作用的了。
从上面的例子中了解到 temperature 参数影响着概率分布的平滑程度。它的实现方式就是对 logits 进行缩放。引入 temperature 参数后,Softmax 函数的公式变为:
$$ P(token_i) = softmax(\frac{logit_i}{T}) $$
其中 $T$ 是 temperature 参数。
Softmax 函数能够反映出 logits 的差异程度。而 logits 除以 temperature 后,由于除法的特性,若 $T < 1$,则会放大 logits 的差异,使得高分词的概率更高,低分词的概率更低;若 $T > 1$,则会缩小 logits 的差异,使得低分词的概率被提升。
Temperature 的范围是 (0, 2]
所以这就能看出为什么 temperature 值大小范围是在 (0, 2] 之间,因为使用的是除法,只有当 T 小于 1 时,才会使得高分词的概率更高,而当 T 大于 1 时,低分词的概率才会被提升。但又不能让 T 无限制增大,否则就会导致输出完全随机,LLM 也就失去了意义。
Top-p 的工作原理
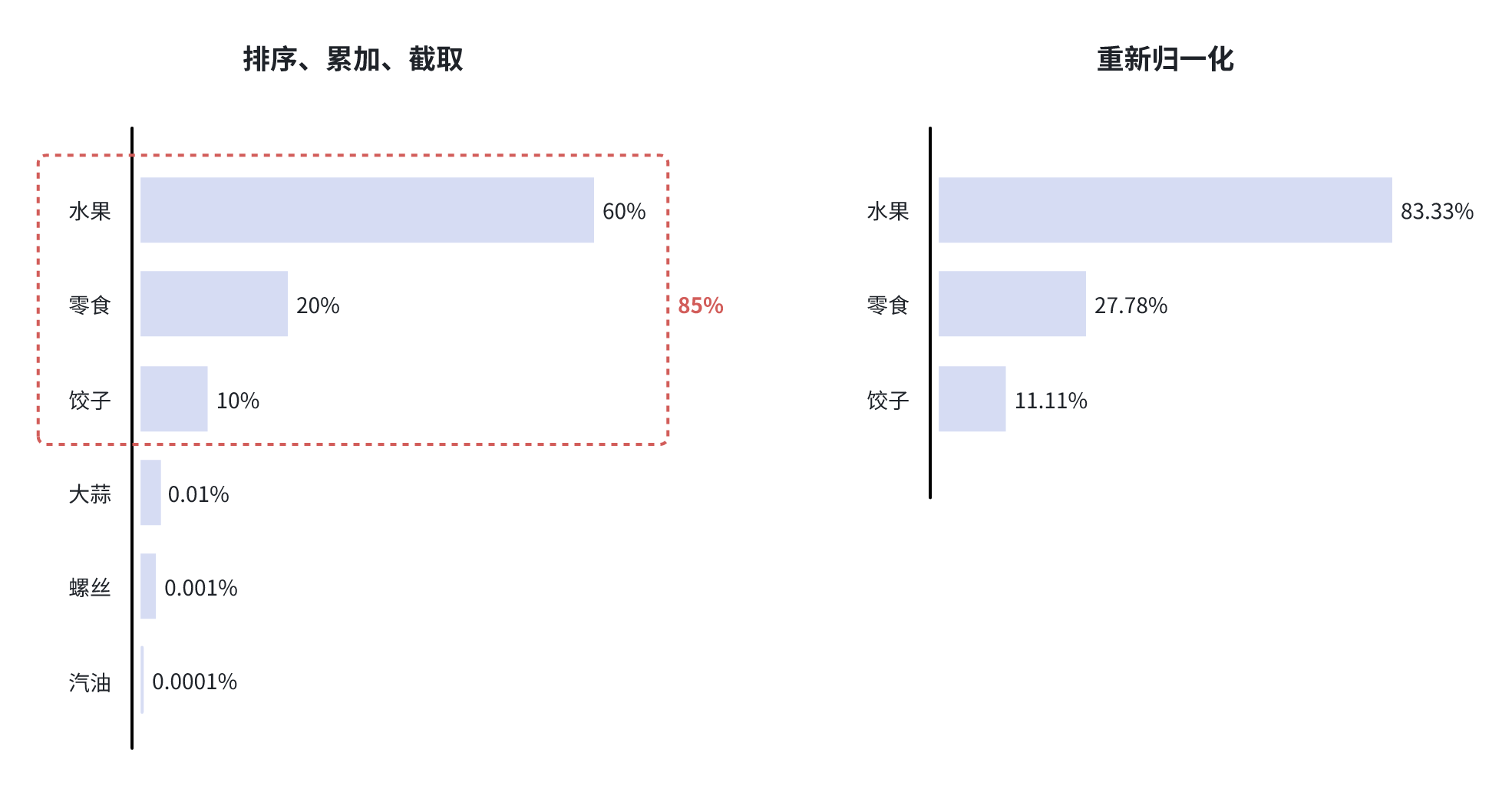
top_p 的实现方式显而易见了,分为以下几个步骤:
- 排序:将所有 token 按照概率从高到低排序。
- 累加:从概率最高的 token 开始,逐个累加它们的概率,直到累计概率大于等于
top_p的值。 - 截断:只保留那些累计概率在
top_p范围内的 token(包括最后一个超过top_p的 token)。 - 重新归一化:对保留的 token 的概率进行归一化处理,使它们的总和为 1。
Temperature 和 Top-p 设置参考
不同的任务需要不同的创造力 or 保守程度。以下是一些常见的 temperature 和 top_p 设置建议:
| 用例 | Temperature | Top-p | 描述 |
|---|---|---|---|
| 代码生成 | 0.2 | 0.1 | 生成符合既定模式和约定的代码。输出更具确定性和针对性。有助于生成语法正确的代码。 |
| 创意写作 | 0.7 | 0.8 | 生成富有创意且多样化的叙事文本。输出更具探索性,且不受模式限制。 |
| 聊天机器人回复 | 0.5 | 0.5 | 生成兼顾连贯性和多样性的对话回复。输出结果更加自然、引人入胜。 |
| 代码注释生成 | 0.3 | 0.2 | 生成更简洁、更相关的代码注释。输出更具确定性,并符合规范。 |
| 数据分析脚本 | 0.2 | 0.1 | 生成更准确、更高效的数据分析脚本。输出结果更具确定性和针对性。 |
表格参考自 Cheat Sheet: Mastering Temperature and Top-p in ChatGPT API
二者的执行顺序
网络上很少关于 temperature 和 top_p 的执行顺序的资料。所以直接找到 Transformer 源码老家,看看具体实现。
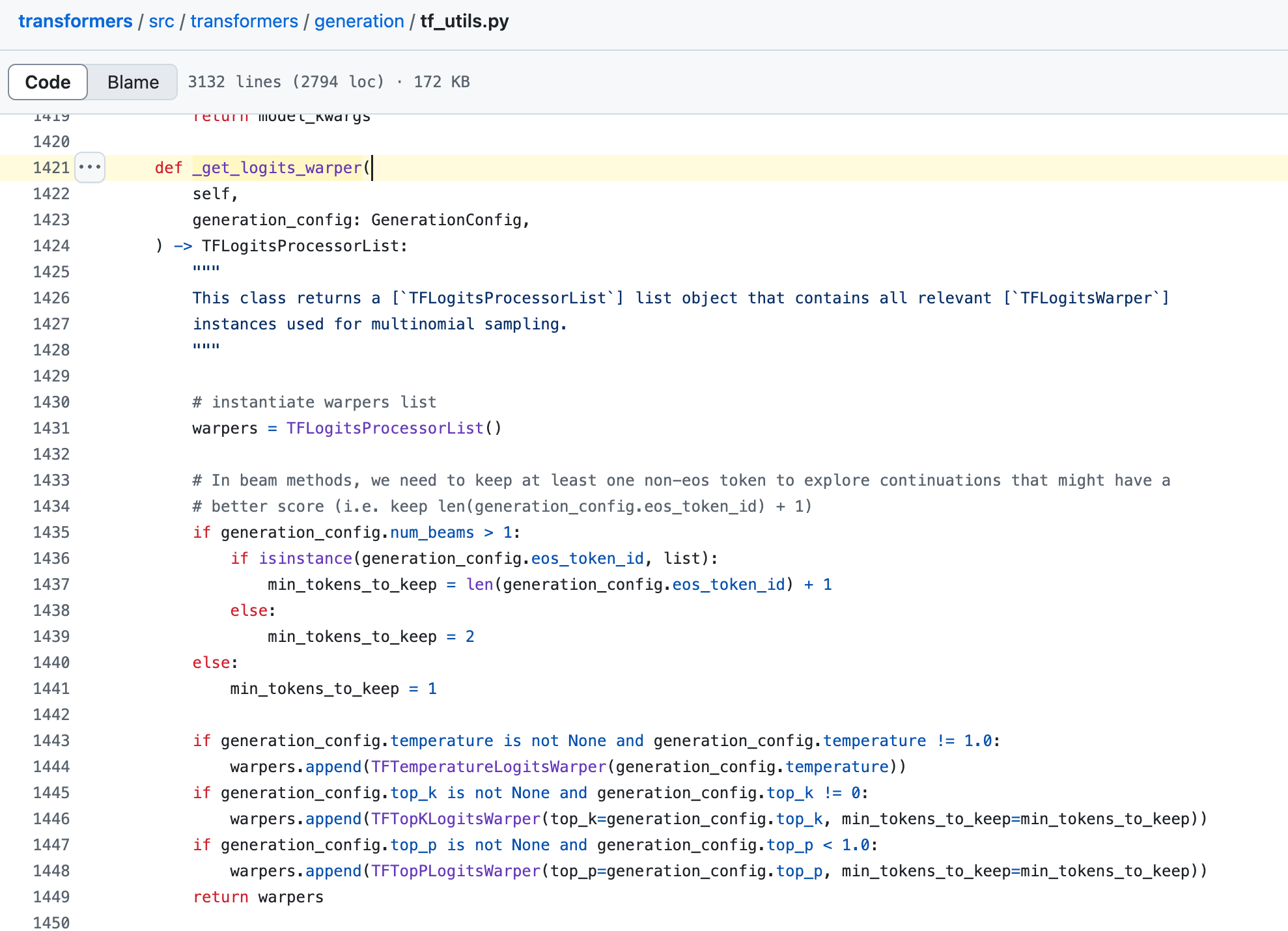
定位到 _get_logits_warper 函数,这个函数负责处理 logits 的变换,这里按顺序往一个 warper(TFLogitsProcessorList 的实例)中插入了 temperature、top_k 和 top_p 的处理器(TF***LogitsWarper)。
接着看一下 TFLogitsProcessorList 这个类的方法,发现只有 __call__ 方法,也就是可以将该 warper 进行调用,具体逻辑是使用 for 循环按序调用每个处理器。
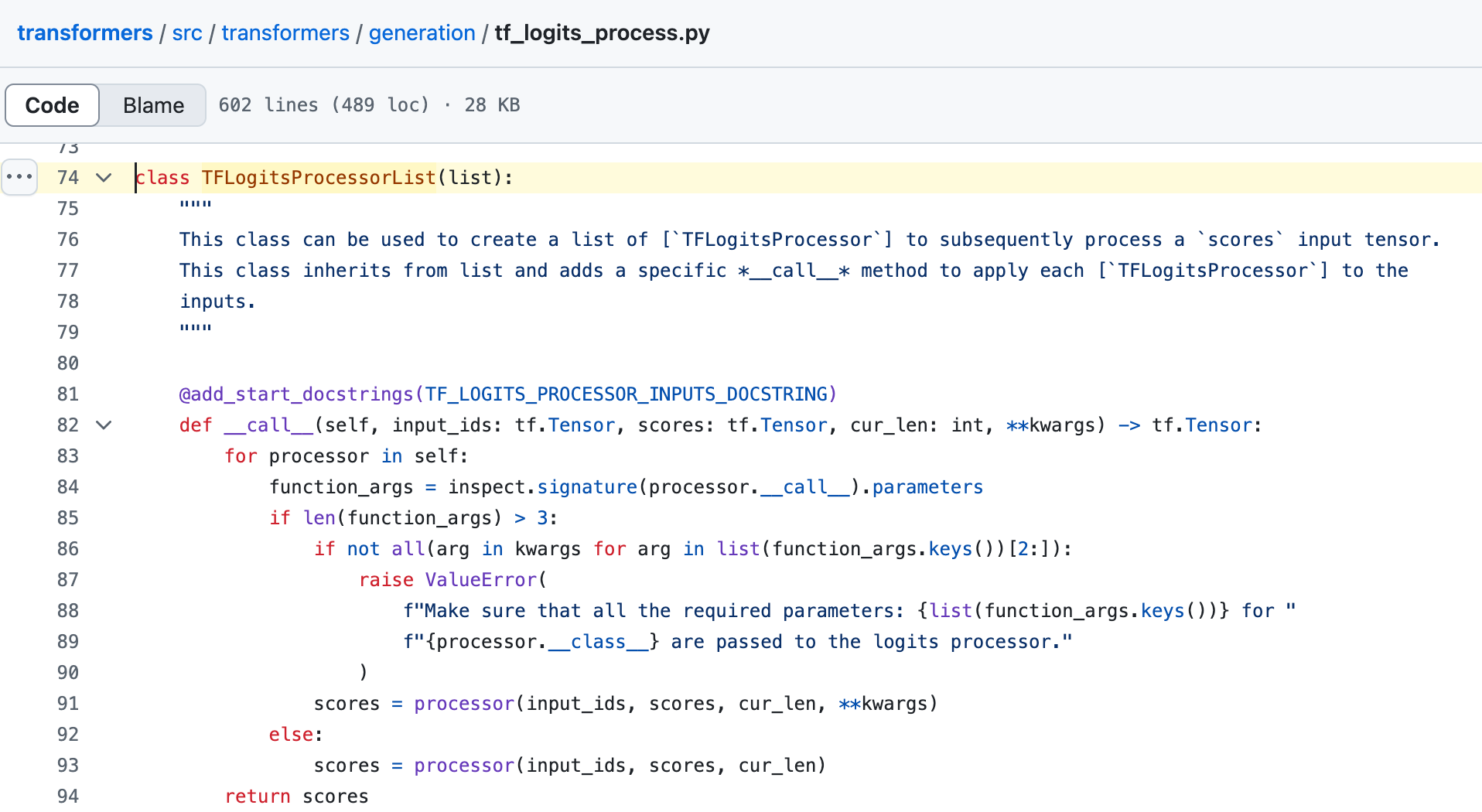
所以,temperature 和 top_p 两个参数的应用顺序为:先应用 temperature,再应用 top_p。
对业务的思考
在实际业务中,作为 LLM 应用层开发者的我们不只有 All in Prompt Engineering 这条路来提升模型表现,也可以利用 temperature 这类采样参数进行精细化调控。像 LangChain、Eino 等框架,都提供了调整 temperature、top_p 等参数的能力(详见文档)。 在构建多 Agent 系统时,我们要对每个 Agent 的职责进行明确划分,并对其采样参数进行量身定制,做到控制 Agent 的输出风格和内容质量。
其他常用参数 除了以上,大语言模型的 API 还提供了其他一些的参数:
- max_tokens: 控制生成文本的最大长度(以 token 计)。这是一个非常实用的参数,可以用来防止模型生成过长的、不必要的文本,同时也能帮助控制 API 的成本。
- 高max_tokens:LLM 输出长度⬆︎
- 低max_tokens:LLM 输出长度⬇︎
- presence_penalty: 存在惩罚。通过对已经出现过的 token 施加惩罚,来鼓励模型引入新的话题和概念,降低重复性。数值越高,模型越倾向于谈论新内容。
- 高 presence_penalty(p -> 2):多元化⬆︎,重复度⬇︎
- 低 presence_penalty(p -> -2):多元化⬇︎,重复度⬆︎
- frequency_penalty: 频率惩罚。与存在惩罚类似,但它是根据 token 出现的频率来施加惩罚的。一个词出现的次数越多,受到的惩罚就越大,这能有效减少模型重复使用相同的词语。
- 高 presence_penalty(p -> 2):多元化⬆︎,重复度⬇︎
- 低 presence_penalty(p -> -2):多元化⬇︎,重复度⬆︎
- stop (或 stop_sequences): 指定一个或多个字符串序列。当模型生成这些序列时,会立即停止输出。这对于控制生成内容的结束点非常有用,比如在生成列表或对话时。